Sistemas de Recuperación de Información Textual
Introducción
Resumen
Empezaremos por definir qué son los sistemas de recuperación de información textual: “La recuperación de información es el proceso de selección, en un fondo documental, de la información más adecuada a las demandas de los usuarios”.
En este trabajo trataremos el caso de los documentos digitales y sus distintos formatos, y su recuperación mediante Internet. Recordemos que Internet es un conjunto descentralizado de redes de comunicación interconectadas que utilizan la familia de protocolos TCP/IP, garantizando que las redes físicas heterogéneas que la componen funcionen como una red lógica única, de alcance mundial.
El principal problema que nos plantea Internet es el gran volumen de datos de todo tipo (texto, imágenes, audio y vídeo, y en múltiples formatos), que además son volátiles, ya que continuamente aparecen y desaparecen nuevas páginas web. Además, No se conoce a priori la estructura de la información, y gran parte se genera dinámicamente mediante consultas a bases de datos, llegando a producirse una redundancia de la información.
Buscadores de recursos
Los buscadores de recursos se pueden clasificar según su organización y funcionamiento en:
- Índices o directorios, que catalogan y organizan la información por
categorías.
- Son catálogos Web con recursos clasificados y organizados por categorías y subcategorías.
- Existen directorios generales y directorios temáticos.
- Motores de búsqueda, que son programas que buscan a través de bases
de datos de documentos HTML. Hay de dos tipos.
- Buscadores sin robot.
- Buscadores con robot.
- Motores de decisión, determinan cual es la respuesta o solución concreta a una pregunta o decisión.
- Buscadores de bitácoras, buscan en el contenido de blogs o weblogs.
- Buscadores Temáticos , buscan cualquier tipo de recurso o campo específico que podamos imaginar.
Además, los buscadores de recursos también se pueden clasificar según el número de bases de datos a las que acceden:
- Acceso a una sola base de datos.
- Multibuscadores: a varias bases de datos secuencialmente.
- Metabuscadores: a varias bases de datos simultáneamente.
Motores de búsqueda
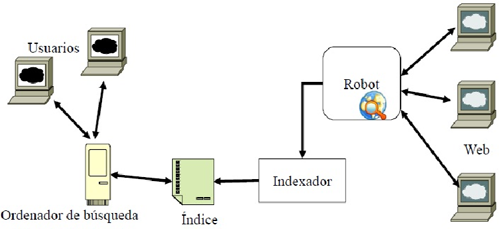
Un motor de búsqueda es un sistema informático que busca archivos almacenados en servidores web gracias a su «spider» (o Web crawler). Un ejemplo son los buscadores de Internet (algunos buscan sólo en la Web pero otros buscan además en noticias, servicios como Gopher, FTP, etc.) cuando se pide información sobre algún tema. Las búsquedas se hacen con palabras clave o con árboles jerárquicos por temas; el resultado de la búsqueda es un listado de direcciones Web en los que se mencionan temas relacionados con las palabras clave buscadas. El principal problema que presentan es recorrer la Web actualizando y agregando nuevas páginas, pues como ya dijimos Internet tiene una gran cantidad de información volátil.
Usan el paradigma de recuperación en texto completo, y todas las palabras de un documento se almacenan en un documento para su posterior recuperación. Se pueden clasificar en dos tipos:
- Motores de búsqueda sin robot.
- Es necesario dar de alta las páginas para figurar en su base de datos.
- Los contenidos en ocasiones son analizados por personas que visitan la dirección ańadida y comprueban que cumple los requisitos para ser dado de alta.
- Motores de búsqueda con robor.
- Son programas que buscan a través de la estructura del hipertexto recuperando enlaces.
Respecto a las funciones del robot, es conveniente saber que utilizan diferentes estrategias para elegir las Web a visitar, que es habitual que almacene una lista histórica de URL, y cada página modificada o nueva que encuentra es procesada. Además se analizan las páginas de la lista extrayéndose de ella otras páginas, que si son nuevas, se agregan a la lista de páginas a recorrer. Por último, no es necesario dar de alta un sitio Web para aparecer en el buscador.
Normalmente se indexan los títulos HTML (etiqueta TITLE) y los primeros párrafos. En ocasiones también las palabras contenidas en el documento excluyendo las de uso común. Se indexan también los metadatos contenidos en las etiquetas META de la cabecera HTML, por lo que es importante utilizar correctamente las palabras clave dentro del HTML. Y para terminar, también se indexan textos alternativos a las imágenes.
Motores de decisión
Un sistema de apoyo a las decisiones (DSS por sus siglas en inglés Decision support system) son aplicaciones informáticas que realizan una función de apoyo. No cuenta con una base de datos compuesta de páginas web indexadas, sino con una base de conocimiento y una serie de reglas que le permiten operar sobre ella.
Buscadores de bitácoras
Un blog, o en espańol también una bitácora, es un sitio web periódicamente actualizado que recopila cronológicamente textos o artículos de uno o varios autores, apareciendo primero el más reciente, donde el autor conserva siempre la libertad de dejar publicado lo que crea pertinente. El nombre bitácora está basado en los cuadernos de bitácora, cuadernos de viaje que se utilizaban en los barcos para relatar el desarrollo del viaje y que se guardaban en la bitácora. Aunque el nombre se ha popularizado en los últimos ańos a raíz de su utilización en diferentes ámbitos, el cuaderno de trabajo o bitácora ha sido utilizado desde siempre.
Los buscadores de bitácoras se basan en nubes de tags, es decir, tienen un área de la página en la que aparecen las marcas más populares, normalmente con un tamańo proporcional al número de entradas publicadas que hacen referencia a ellas. Por otro lado, no rastrean la Web como hacen los buscadores, sino que las propias bitácoras envían una seńal al buscador cuando se actualizan.
Directorios
Un directorio es una agrupación de archivos de datos, atendiendo a su contenido, a su propósito o a cualquier criterio que decida el usuario. Técnicamente el directorio almacena información acerca de los archivos que contiene, como los atributos de los archivos o dónde se encuentran físicamente en el dispositivo de almacenamiento. Se crean de forma manual, recopilando las direcciones de los sitios y asociándoles a una o más categorías o descripciones.
Técnicas de búsqueda
Técnicas de recuperación de la información con motores de búsqueda
El procedimiento a seguir consiste, primero y principal, en definir bien el objetivo de la búsqueda, después utilizar estrategias de búsqueda de acuerdo al objetivo, para pasar a ordenarlas según su eficacia y eficiencia y, si no se han obtenido los resultados esperados hay que replantear la estrategia y/o buscadores de recursos (directorios, motores de búsqueda conceptuales).
Estrategias de búsqueda en la web
Características de la búsqueda |
Estrategias |
Nmbre o frase distintiva:
|
“Phrase searching” es una característica que quieres en cada herramienta
de búsqueda que elijas:
|
| Algunos de los términos pueden ser palabras comunes con muchos significados y contextos. | “Booleano and” será quien nos ayude. |
| Si se anticipan muchos resultados con términos que no se quieren. | “Boolea and not” será de gran ayuda. |
| Si hay sinónimos, variaciones de una palabra, o deletreado extranjero para alguno de los términos. | “Booleano or” será quien nos ayude. |
| Cuando se está buscando por home pages y/o otros documentos, principalmente utilizando términos. | Hay que limitarlo a los campos del título de los documentos con “intitle”. |
| Si se está buscando por términos que tengan muchas terminaciones. | Algunos sistemas buscan las terminaciones de algunos nombres de manera automática. Pero es recomendable usar “or” en las búsquedas. |
Estrategias de búsqueda avanzadas en
Google
- Búsquedas en la dirección de la página: inurl
- Búsquedas en el título: intitle
- Búsquedas en los hipervínculos: inanchor
- Documentos en un cierto formato: filetype
- Páginas que apuntan a otras: link
- Búsqueda de palabras cercanas: *
- Búsqueda de Definiciones: define
- Búsqueda de Sinónimos: intitle:~
- Información sobre un sito: info
- Búsqueda de Sitios relacionados: related
- Búsqueda dentro de un dominio: site
Estrategias de búsqueda avanzadas en
Bing
- Enlaces a documentos de tipo específico: contains
- Para encontrar páginas alojadas en un determinado host con la
dirección ip que se quiere: ip
- Buscar en un determinado idioma: language
- Para encontrar páginas que contengan una determinada palabra en el
“body” de una página: inbody
- Para encontrar páginas que contengan una determinada palabra en el
“title” de una página: intitle
- Para limitar la búsqueda a un dominio específico: site: .org, site:
.gov, site: .edu
- Para encontrar páginas que en el url contengan unos determinados
términos: url
- Para obtener sitios web que contengan un sistema de subscripcion
(RSS o ATOM): hasfeed
Comparativa de consultas entre diferentes
buscadores
Acción |
żCómo? |
żEn qué buscadores? |
| Debe incluir un término | + | Todos |
| Debe excluir un término | - | Todos |
| Debe incluir una frase | " " | Todos |
| Deben coincidir todos los términos | Automática | Todos |
| Que coincida cualquier término | Por búsqueda avanzada | AllTheWeb, AltaVista, Google, Lycos, MSN Search, Teoma, Yahoo |
| Que coincida cualquier término | OR | AltaVista, AOL Search, Ask Jeeves, MSN Search, Teoma, Yahoo (se debe hacer en mayúsculas) AllTheWeb, Lycos (sólo para dos palabras) |
| Búsqueda por título: | title: | AltaVista, AllTheWeb, Inktomi |
| Búsqueda por título: | intitle: | Google, Bing, Teoma |
| Búsqueda por título: | allintitle: | |
| Búsqueda basada en el “site” | host: | Altavista |
| Búsqueda basada en el “site” | site: | Excite, Google (Netscape, Yahoo), Bing |
| Búsqueda basada en el “site” | url.host: | AllTheWeb, Lycos (for AllTheWeb results only) |
| Búsqueda basada en el “site” | domain: | Inktomi (HotBot, iWon, LookSmart) |
| Búsqueda basada en el “site” | none | AOL, Direct Hit, HotBot, LookSmart, Lycos, MSN, Netscape, Northern Light, Open Directory, Yahoo |
| Búsqueda basada en el “URL” | url: | AltaVista, Excite, Northern Light, Bing |
| Búsqueda basada en el “URL” | url.all: | AllTheWeb, Lycos (sólo para resultados de AllTheWeb) |
| Búsqueda basada en el “URL” | allinurl: inurl: | |
| Búsqueda basada en el “URL” | originurl: | Inktomi, (AOL, GoTo, HotBot) |
| Búsqueda basada en el “URL” | u: | Yahoo |
| Búsqueda basada en el “URL” | none | AOL, Direct Hit, HotBot, LookSmart, MSN, Bing, Open Directory |
| Búsqueda basada en el “Link” | link: | AltaVista, Google, Northern Light |
| Búsqueda basada en el “Link” | linkdomain: | Inktomi (AOL, HotBot, iWon, MSN) |
| Búsqueda basada en el “Link” | link.all: | AllTheWeb, Lycos (sólo para resultados de AllTheWeb) |
| Búsqueda basada en el “Link” | none | AOL, Direct Hit, Excite, HotBot, LookSmart, Northern Light, Netscape, Yahoo |
| Carácter Comodín | * | AltaVista, Inktomi (iWon), Northern Light, Yahoo |
| Carácter Comodín | ? | AOL Search, Inktomi (iWon) |
| Carácter Comodín | % | Northern Light |
| Carácter Comodín | Ninguno | AllTheWeb, Direct Hit, Excite, Google, HotBot, LookSmart, Lycos, MSN |
Otros operadores de búsqueda menos frecuentes
- ADJ (adyacente): cuando se desean encontrar documento con los términos cerca, en cualquier orden.
- NEAR (cerca): cuando los términos deban aparecer en las 25 palabras próximas.
- FAR (lejos): los términos aparecen con 25 palabras o más de distancia.
- BEFORE (antes): similar a AND pero con los términos en un orden preciso.
Bibliografía
Compendio de las diversas fuentes consultadas para la realización de este trabajo.
- Apuntes de la asignatura Informática II del Grado en Información y Documentación.
- http://es.wikipedia.org
- http://www.google.es/
- http://www.arxiver s.com/idadmin/docs/17_03.pdf
Enlaces de interés
Compendio de los diversos enlaces relacionados con el tema tratado en este trabajo.http://es.wikipedia.org