Hoy en día los sistemas informáticos
se caracterizan por la rápida evolución de los componentes hardware, que
incrementan continuamente sus prestaciones junto con una fuerte tendencia a la
estandarización y una gran diversidad de marcas y modelos con prestaciones y
precios similares. Es por todo ello, que las prestaciones de los grandes
ordenadores de años anteriores hoy en día están disponibles en un ordenador
personal. El software es el mecanismo es el mecanismo que nos permite utilizar y
explotar ese potencial.
Todo esto hace que a la hora de plantearnos comprar un sistema informático completo destinado a cualquier tipo de actividad (gestión de empresa, procesos industriales, uso doméstico, etc.), el software es lo que va a marcar la diferencia. Siempre entre equipos con características similares elegiremos aquéllas compañías con mayores prestaciones, calidad y facilidad de uso de su software.
Por otro lado, decir que debido a la complejidad de los actuales sistemas informáticos, el desarrollo del software no es nada fácil, haciendo necesario en muchas ocasiones proyectos con decenas de miles de líneas de códigos. No se puede programar sin más, es necesario analizar lo que tenemos que hacer, cómo lo vamos a hacer y cómo se van a coordinar las distintas personas que intervienen en el proyecto para llegar a obtener los resultados inicialmente esperados.
Por lo visto anteriormente, podemos decir que el software, es el componente cuyo desarrollo presenta mayores dificultades, ya sea por su planificación, el no cumplimiento de las estimaciones de costes iniciales, etcétera. Pero todo es debido a que es una actividad reciente si la comparamos con otras actividades de ingeniería, y aún es más reciente la disciplina que establece el orden en el desarrollo de sistemas de software partiendo el problema, quizás, en que no están lo suficientemente difundidos o valorados.
1.2. Evolución de la industria del software.
En el comienzo de la informática, el hardware tenía mucha mayor importancia que en la actualidad, su coste era mucho mayor, y su fiabilidad, capacidad de almacenamiento y procesamiento era lo que determinaba las prestaciones de un determinado producto. El software pasaba a un segundo plano, no se le daba mucha importancia, la mayoría se desarrollaba y era usado por la misma persona, siendo ella misma quien lo escribía, ejecutaba y si fallaba, lo depuraba. El diseño estaba en la mente de alguien y la documentación no existía, si algo fallaba siempre estaría esa persona para subsanar el error.
Dada esta situación, las empresas se dedicaron a la mejora de las prestaciones de los equipos en lo que se refiere al hardware, reduciendo los costes y aumentando la velocidad de cálculo y capacidad de almacenamiento. Debido a esto el hardware se desarrolló rápidamente y los sistemas informáticos cada vez eran más complejos necesitando un software, a su vez, más complejo para su funcionamiento. Es entonces cuando surgen las primeras casas dedicadas al software y comienza la movilidad laboral, por lo que con la marcha de un trabajador era poco probable el mantenimiento o modificación de los programas desarrollados por éste.
Al no existir una metodología y una documentación consistente, los programas presentaban, en muchas ocasiones errores e inconsistencias, por lo que estaban en una continua depuración elevando así los costes de los mismos. Era más rápido en muchas ocasiones, comenzar de cero que modificar lo que ya estaba hecho, pero no por ello estaban exentos de errores y futuras modificaciones, por lo que la situación volvía a ser la misma.
Hoy en día, todo ha cambiado y el software pasa a ser el elemento principal del coste frente al hardware, lo cual a llevado a la aparición y desarrollo de nuevas tecnologías que enfocan integralmente el problema abarcando todas sus fases, que en su mayoría no se consideraban en los desarrollos tradicionales, y que son fundamentales en la reducción de costes y plazos, así como la calidad del producto final. Es lo que llamamos la ingeniería del software, definiéndose como “el tratamiento sistemático de todas las fases del ciclo de vida del software”.
1.3. Características del software.
Una definición de software podría ser la siguiente:
Software: instrucciones de ordenador
que cuando se ejecutan proporcionan la función y el comportamiento deseado,
estructuras de datos que facilitan a los programas manipular adecuadamente la
información, y documentos que describen la operación y el uso de los
programas.
Por ello, decir tiene que el software incluye no sólo los programas de ordenador, sino también las estructuras de datos que manejan esos programas y la documentación que se adjunta del proceso de desarrollo, mantenimiento y uso de dichos programas.
Según esto, mientras el hardware es algo físico, material, el software es inmaterial y por ello tiene unas características completamente distintas. Algunas de ellas pueden ser:
· El software se desarrolla, no se fabrica en sí.
Tanto en el proceso de desarrollo del software como del hardware se siguen unas fases de análisis, diseño y desarrollo o construcción, obteniendo un buen producto final dependiendo de la calidad del diseño.
En el caso de producción de hardware a gran escala, el coste del producto
depende del coste de los materiales empleados y del propio proceso de producción,
no influyendo tanto en el coste las fases previas de ingeniería. En cambio en
el caso del software, el desarrollo es una más de las labores de ingeniería, y
la producción a gran o pequeña escala no influye en el impacto que tiene la
ingeniería en el coste, al ser un producto inmaterial. Por otro lado, el
software no presenta problemas técnicos y no requiere un control de calidad
individualizado, cosa que si que ocurre en el hardware.
Los costes del software radican en el desarrollo de la ingeniería y no en la producción, y es ahí donde hay que incidir para reducir el coste final del producto.
· El software no se estropea.
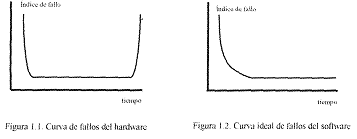
Partiendo tanto de la figura 1.1, como de la figura 1.2, podemos observar como por un lado el hardware (figura 1.1.), tiene la llamada curva de bañera, que indica que tiene muchos fallos al principio de su vida, debidos en gran parte a los defectos de diseño o a la baja calidad inicial de la fase de producción. Dichos defectos se van subsanando hasta llegar a un nivel estacionario, pero los fallos vuelven a incrementarse debido al deterioro de los componentes (suciedad, vibraciones u otros factores externos) por lo que hay que sustituir los componentes defectuosos por otros nuevos para que la tasa de fallos vuelva a estar a un nivel estacionario.
|
|
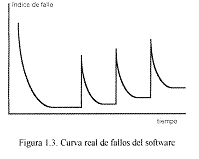
Por otro lado observamos que en el caso del software (figura 1.2.), inicialmente la tasa de fallos es alta, por errores no detectados durante su desarrollo, pero que una vez corregidos y dado que no está expuesto a factores de deterioro externos, la tasa de fallos debería alcanzar un nivel estacionario y mantenerse definitivamente.
Todo esto no es más que una simplificación del modelo real de fallos de un producto software. Durante su vida, el software va sufriendo cambios debido a su mantenimiento, el cual puede orientarse tanto a la corrección de errores como a cambios en los requisitos iniciales del producto. Al realizar los cambios es posible que se produzcan nuevos errores con lo cual se manifiestan picos en la curva de fallos.
Estos errores pueden corregirse, pero los sucesivos cambios, hacen que el producto se aleje cada vez más de las especificaciones iniciales de acuerdo a las cuales fue desarrollado, conteniendo cada vez más errores. Además, a veces, se solicita un nuevo cambio antes de haber corregido todos los errores producidos por el cambio anterior.
Por todo ello, como vemos en la figura 1.3, el nivel estacionario que se consigue después de un cambio es algo superior al que había antes de efectuarlo, degradándose poco a poco el funcionamiento del sistema. De esta manera, podemos decir que el software no se estropea, pero se deteriora.
|
|
Además, hay que decir, que cuando un componente software se deteriora, al contrario que ocurre en el hardware, no podemos sustituirlo por otro porque no existen “piezas de repuesto”. Cada fallo indica un fallo en el diseño o en el proceso por el que se transformó el diseño en código máquina ejecutable. La solución está en sustituir el diseño por otro así como el desarrollo del producto.
· La mayoría del software se construye a medida.
En el caso del hardware el diseño se realiza con
componentes digitales existentes en catálogo que han sido probados por el
fabricante y usuarios anteriores, teniendo unas especificaciones claras y
estando bien definidos. Con el software no ocurre así. No existen catálogos de
componentes, y aunque productos como sistemas operativos, editores, entornos de
ventanas y bases de datos se venden en grandes ediciones, la gran mayoría del
software se fabrica a medida, siendo su reutilización muy baja.
Se puede comprar software ya desarrollado, pero como unidades completas, no como componentes que pueden ser reensamblados para construir nuevos programas. Esto hace que el coste de ingeniería sobre el producto final sea muy elevado.
A lo largo de los años se ha intentado la reutilización del software pero tras muchos intentos ha habido poco éxito. Un ejemplo claro de reutilización son las bibliotecas que se empezaron a desarrollar en los años sesenta como subrutinas científicas, reutilizables en muchas aplicaciones científicas y de ingeniería, así como hoy en día la mayor parte de los lenguajes modernos incluyen bibliotecas de este tipo. Sin embargo, existen otros problemas como la búsqueda de un elemento en una estructura de datos, debido a la gran variación que existe en cuanto a la organización interna de estas estructuras y en la composición de los datos que la contienen, por lo que, aunque existen algoritmos para resolver estos problemas, no queda más remedio que programarlos una y otra vez, adaptándolos a cada situación particular.
Un nuevo intento de conseguir la reutilización se produjo con el uso de técnicas de programación estructurada y modular. Sin embargo, se dedica por lo general poco esfuerzo al diseño de módulos lo suficientemente generales para ser reutilizables, y en todo caso, no se documentan ni se difunden lo suficiente para extender su uso, con lo cual se tiende a diseñar y programar módulos muy semejantes una y otra vez. La programación estructurada permite diseñar programas con una estructura más clara y más fácil de entender, lo cual permite la reutilización de módulos dentro de los programas o incluso dentro del proyecto que se está desarrollando, pero la reutilización de código en proyectos es muy baja.
La última tendencia es el uso de técnicas orientadas a objetos, que permiten la programación por especialización. Los objetos disponen de interfaces claras y los errores cometidos en su desarrollo pueden ser depurados sin que esto afecte a la corrección de otras partes del código y pueden ser heredados y reescritos parcialmente, haciendo posible su reutilización aún en situaciones no contempladas en el diseño inicial.
1.4. Aplicaciones del software.
El software puede aplicarse a numerosas situaciones del mundo real. En primer lugar, diremos que puede aplicarse a todos aquellos problemas para los que se ha establecido un conjunto de acciones que lleven a su resolución (algoritmo). En estos casos, usamos lenguajes para implementar estos algoritmos.
Es difícil establecer categorías genéricas para las aplicaciones del software. Cuanto más complejo es el mismo más complicado se hace establecer compartimentos claramente separados. No obstante, se suele aceptar esta clasificación:
Formado por aquellos programas cuyo fin es servir al desarrollo o al funcionamiento de otros programas. Este tipo de programas son muy variados: editores, compiladores, sistemas operativos, entornos gráficos, programas de telecomunicaciones, etc., pero todos ellos tienen unos puntos en común y como estar muy próximos al hardware, ser utilizados por numerosos usuarios y por ser programas de difusión, no están diseñados normalmente a medida. Esto permite un mayor diseño y optimización, pero también les obliga a ser muy fiables, cumpliendo estrictamente las especificaciones para las que fueron creados.
1.4.2. Software de tiempo real
Formado por aquellos programas que miden, analizan y controlan los sucesos del mundo real a medida que ocurren, debiendo reaccionar de forma correcta a los estímulos de entrada en un tiempo máximo prefijado. Deben, por tanto, cumplir unos requisitos temporales muy estrictos, además de ser fiables y tolerantes a fallos. Por otro lado, no suelen ser muy complejos y precisan de poca interacción con el usuario.
Este tipo de programas utiliza grandes cantidades de información almacenadas en bases de datos para poder facilitar las transacciones comerciales o la toma de decisiones. Además de las tareas convencionales de procesamiento de datos, en las que el tiempo de procesamiento no es crítico y los errores pueden ser corregidos a posteriori, incluyen programas interactivos que sirven de soporte a las transacciones comerciales.
1.4.4. Software científico y de ingeniería.
Es otro de los campos clásicos de aplicación de la informática. Se encarga de realizar complejos cálculos sobre datos numéricos de todo tipo. En este caso un requisito básico que deben cumplir es la corrección y exactitud de las operaciones que realizan.
Este campo se ha ampliado últimamente con el desarrollo de los sistemas de diseño, ingeniería y fabricación asistida por ordenador (CAD, CAE y CAM), lo simuladores gráficos y otras aplicaciones interactivas que lo acercan al software de tiempo real e incluso al de sistemas.
1.4.5. Software de ordenadores personales.
El uso de ordenadores personales y de uso doméstico se ha extendido a lo largo de la última década. Aplicaciones típicas son los procesadores de texto, las hojas de cálculo, bases de datos, aplicaciones gráficas, juegos, etcétera. Son productos de amplia difusión orientados a usuarios no profesionales, por lo que sus principales requisitos son la facilidad en el uso y el bajo coste.
Es aquél que va instalado en otros productos industriales, como por ejemplo la electrónica de consumo, dotando a estos productos de un grado de inteligencia cada vez mayor. Se aplica a todo tipo de productos, desde un vídeo doméstico hasta un misil con cabeza nuclear, pasando por sistemas de control de los automóviles, y realiza funciones muy diversas, desde complicados cálculos en tiempo real a sencillas interacciones con el usuario facilitando el manejo del aparato que los incorpora. Comparten características con el software de sistemas, el de tiempo real, el de ingeniería y científico y el de ordenadores personales.
1.4.7. Software de inteligencia artificial.
El software basado en lenguajes procedimentales es útil para realizar de forma rápida y fiable operaciones que para el ser humano son tediosas e incluso inabordables. Sin embargo, es difícil su aplicación a problemas que requieran funciones intelectuales más elevadas. Esta deficiencia trata de subsanarla el software de inteligencia artificial, basándose en el uso de lenguajes declarativos, sistemas expertos y redes neuronales.
Como hemos visto, el software permite aplicaciones muy diversas, pero en todas ellas encontramos algo en común: el objetivo es que el software determine una determinada función cumpliendo, a su vez, una serie de requisitos (fiabilidad, corrección, respuesta en un tiempo determinado, facilidad de uso, bajo coste, etcétera) a la hora de desarrollar el software.
A lo largo del tiempo, ya hemos visto que el software ha sufrido lo que se llama “crisis del software”. Dicha crisis vino como consecuencia de los problemas surgidos al desarrollar un software de cierta complejidad y que hoy en día también existen sin que se haya avanzado mucho en los intentos por darle una solución.
Estos problemas son causados por las propias características del software y por los errores cometidos por quienes intervienen en su producción. Entre ellos podemos citar:
La planificación y la estimación de costes son muy imprecisas.
Al comenzar un proyecto de cierta complejidad es frecuente que surjan imprevistos que no estaban recogidos en la planificación inicial, y como consecuencia se producirá un cambio en los costes del proyecto. Sin embargo, en el desarrollo del software lo más frecuente es que la planificación sea prácticamente inexistente, y que nunca se revise en el desarrollo del proyecto. Sin una planificación detallada es imposible hacer una estimación de costes que tenga alguna posibilidad de cumplirse, y tampoco pueden localizarse las tareas conflictivas que pueden desviar los costes previstos.
Entre las causas de este problema podemos citar:
No se recogen datos sobre el desarrollo de proyectos anteriores, con lo que no se adquiere la experiencia que pueda ser utilizada en nuevos proyectos.
Los gestores de los proyectos no están especializados en la producción de software. Es decir, de siempre los responsables del desarrollo del software han sido ejecutivos de medio y alto nivel sin conocimientos de informática, por lo que, si bien es cierto que siempre se ha dicho que un buen gestor puede gestionar cualquier proyecto, no cabe duda que también es necesario conocer las características específicas del software, aprender las técnicas que se aplican en su desarrollo y conocer una tecnología que está en continua evolución.
La productividad es baja.
Los proyectos software tienen, en general, mayor duración de lo que en un principio se esperaba. Como consecuencia de ello los costes se disparan y la productividad y beneficios disminuyen. Un punto importante que influye es la falta de propósitos claros a la hora de comenzar el proyecto. La mayoría del software se desarrolla a partir de unas especificaciones ambiguas e incorrectas sin existir una comunicación con el cliente hasta la entrega del producto. Todo esto no lleva a frecuentes modificaciones de las especificaciones o los cambios de última hora, después de la entrega al cliente. No se realiza un estudio detallado de estos cambios y la complejidad interna de las aplicaciones va creciendo hasta hacerse imposible de mantener y cada modificación, por pequeña que sea, es más costosa y puede ocasionar el fallo de todo el sistema.
Debido a la falta de documentación sobre cómo se ha desarrollado el producto a que las continuas modificaciones han distorsionado el diseño actual, el mantenimiento del software puede llegar a ser una tarea imposible de realizar, pudiendo llevar más tiempo realizar una modificación sobre el programa ya escrito que analizarlo y desarrollarlo entero de nuevo.
La calidad es mala.
Dado que las especificaciones son ambiguas o incluso incorrectas, y que no se realizan pruebas exhaustivas, el software contiene numerosos errores cuando se entrega al cliente. Dichos errores ocasionan un fuerte incremento de costes durante el mantenimiento del proyecto cuando, en realidad, ya se esperaba que estuviese acabado. Recientemente se ha empezado a dar importancia a la prueba sistemática y completa, surgiendo así nuevos conceptos como fiabilidad y garantía de calidad.
El cliente queda insatisfecho.
Debido al poco interés mostrado al análisis de los requisitos del proyecto, la falta de comunicación con el cliente durante el desarrollo y la existencia de numerosos errores en el producto que se entrega, los clientes quedan muy poco satisfechos con los resultados obtenidos. Esto da lugar a que las aplicaciones tengan que ser diseñadas y desarrolladas de nuevo, que no lleguen nunca a utilizarse o que se produzca un cambio de proveedor a la hora de comenzar un nuevo proyecto.
2. DEFINICIÓN DE INGENIERÍA DEL SOFTWARE.
Desarrollar un sistema de software complejo no es algo que puede abordarse sin una preparación previa. El hecho de abordar un proyecto de desarrollo de software como cualquier otro ha llevado a una serie de problemas que limitan nuestra capacidad de aprovechar los recursos que el hardware pone a nuestra disposición.
Los problemas que a lo largo de los años han ido apareciendo no es algo que se va a solucionar en un corto espacio de tiempo pero identificarlos y conocer sus causas es el único método que nos puede ayudar a solucionarlos. La combinación de métodos aplicables a cada una de las fases del desarrollo del software, la construcción de herramientas para automatizar estos métodos, el uso de técnicas para garantizar la calidad de los productos desarrollados y la coordinación de todas las personas que intervienen en el desarrollo de un proyecto, hará que se avance mucho en la solución de estos problemas. De todo esto se encarga la disciplina llamada Ingeniería del Software.
Una definición concreta puede ser:
El establecimiento y uso de principios de ingeniería robustos, orientados a obtener software económico, que sea fiable y funcione de manera eficiente sobre las máquinas.
La ingeniería del software abarca un conjunto de tres elementos clave: métodos, herramientas y procedimientos, que facilitan al gestor el control del proceso de desarrollo y suministran a los implementadores bases para construir de forma productiva software de alta calidad.
Los métodos indican cómo construir técnicamente el software, abarcando amplias tareas de planificación y estimación de proyectos, análisis de requisitos, diseño de estructuras de datos, programas y procedimientos, la codificación, las pruebas y el mantenimiento.
Las herramientas proporcionan un soporte automático o semiautomático para usar los métodos. Existen herramientas para cada una de las fases anteriores y sistemas que integran las herramientas de cada fase de forma que sirven para todo el proceso de desarrollo. Estas herramientas se denominan CASE (Computer Assisted Software Engineering).
Los procedimientos definen la secuencia en que se aplican los métodos, los documentos que requieren, los controles que aseguran la calidad y las directrices que permiten a los gestores evaluar los progresos.
3.
EL CICLO DE VIDA DEL SOFTWARE.
Por ciclo de vida del software, entendemos la sucesión de etapas por las que pasa el software desde que un nuevo proyecto es concebido hasta que se deja de usar. Estas etapas representan el ciclo de actividades involucradas en el desarrollo, uso y mantenimiento de sistemas de software, además de llevar asociadas una serie de documentos que serán la salida de cada una de estas fases y servirán de entrada en la fase siguiente.
Tales actividades son:
Adopción e identificación del sistema: es importante conocer el origen del sistema, así como las motivaciones que impulsaron el desarrollo del sistema (por qué, para qué, etcétera.).
Análisis de requerimientos: identificación de las necesidades del cliente y los usuarios que el sistema debe satisfacer.
Especificación: los requerimientos se realizan en un lenguaje más formal, de manera que se pueda encontrar la función de correspondencia entre las entradas del sistema y las salidas que se supone que genera. Al estar completamente especificado el sistema, se pueden hacer estimaciones cuantitativas del coste, tiempos de diseño y asignación de personal al sistema, así como la planificación general del proyecto.
Especificación de la arquitectura: define las interfaces de interconexión y recursos entre módulos del sistema de manera apropiada para su diseño detallado y administración.
Diseño: en esta etapa, se divide el sistema en partes manejables que, como anteriormente hemos dicho se llaman módulos, y se analizan los elementos que las constituyen. Esto permite afrontar proyectos de muy alta complejidad.
Desarrollo e implementación: codificación y depuración de la etapa de diseño en implementaciones de código fuente operacional.
Integración y prueba del software: ensamble de los componentes de acuerdo a la arquitectura establecida y evaluación del comportamiento de todo el sistema atendiendo a su funcionalidad y eficacia.
Documentación: generación de documentos necesarios para el uso y mantenimiento.
Entrenamiento y uso: instrucciones y guías para los usuarios detallando las posibilidades y limitaciones del sistema, para su uso efectivo.
Mantenimiento del software: actividades para el mantenimiento operativo del sistema. Se clasifican en: evolución, conservación y mantenimiento propiamente dicho.
Existen diversos modelos de ciclo de vida, pero cada uno de ellos va asociado a unos métodos, herramientas y procedimientos que debemos usar a lo largo de un proyecto.
4.1.1.
Modelos descriptivos vs. modelos prescriptivos.
Un
modelo de ciclo de vida del software es una caracterización -descriptiva o
prescriptiva- de la evolución del software.
Los
modelos prescriptivos dictan pautas de cómo deberían desarrollarse los
sistemas de software; por lo tanto son más fáciles de articular ya que los
detalles del desarrollo pueden ser ignorados, generalizados, etc. Esto puede
dejar dudas acerca de la validez y robustez de este tipo de modelos.
Otra
forma de encarar el desarrollo de un modelo es la forma descriptiva, la cual se
basa en la observación del desarrollo de sistemas reales. Son más difíciles
de articular debido a dos razones fundamentales:
La captura de datos es un proceso
que puede tomar años.
Los modelos descriptivos son específicos
a los sistemas observados y solamente generalizables a través de análisis
sistemáticos.
4.1.2. Modelos
tradicionales vs. modelos evolutivos
Aunque
este tipo de modelos son a menudo intuitivos y muy útiles para el
establecimiento de marcos de trabajo, administración y selección de
herramientas para el desarrollo de software, presentan serios problemas:
Fallan para proveer un mecanismo
adecuado que permita gobernar los cambios en el desarrollo del software.
Plantea una organización muy poco
realista que implica una secuencia uniforme y ordenada de actividades de
desarrollo.
La rigidez que este tipo de modelos
impone a los procesos de desarrollo impide que el producto pueda adaptarse dinámicamente
para satisfacer los requerimientos siempre cambiantes. Esto restringe la
creatividad y la productividad.
Son pobres predictores de por qué
ciertos cambios son hechos a un sistema, y por qué los sistemas evolucionan de
maneras similares o diferentes.
Como
una solución a estos problemas surgieron nuevas propuestas que pueden agruparse
bajo el nombre de modelos evolutivos. Los modelos evolutivos presentan las
siguientes características:
Existen tres orientaciones:
centrados en el producto, centrados en los procesos y centrados en la
administración y organización del proceso.
Focalizan la atención en los
mecanismos y procesos que cambian sistemas.
Están caracterizados por el diseño,
desarrollo y despliegue de una capacidad inicial usando tecnología actual que
incluye previsión para la adición evolutiva de futuras capacidades a medida
que se definen nuevos requerimientos y que las tecnologías maduran.
Están menos interesados en la etapa de desarrollo
que en los mecanismos tecnológicos y procesos organizacionales que posibilitan
el surgimiento de sistemas a través del tiempo y del espacio.
4.2. Modelos de Ciclo de Vida del software.
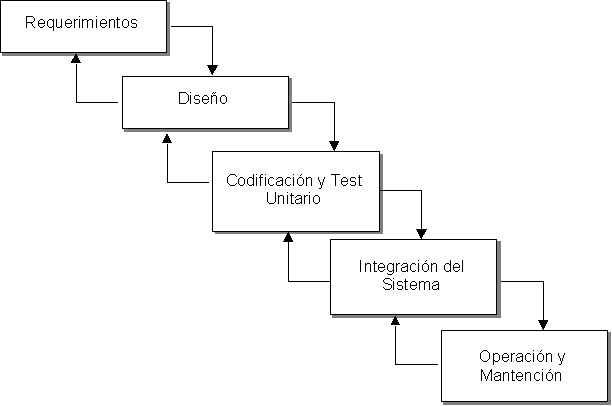
El
modelo cascada (waterfall), propuesto por Royce en 1970, fue derivado de modelos
de actividades de ingeniería con el fin de establecer algo de orden en el
desarrollo de grandes productos de software. Consiste en diferentes etapas, las
cuales son procesadas en una manera lineal. Comparado con otros modelos de
desarrollo de software es más rígido y mejor administrable. El modelo cascada
es un modelo muy importante y ha sido la base de muchos otros modelos, sin
embargo, para muchos proyectos modernos, ha quedado un poco desactualizado.
El
modelo cascada es un modelo de ingeniería diseñado para ser aplicado en el
desarrollo de soft
|
|
Análisis y definición de
requerimientos: en esta etapa, se
establecen los requerimientos del producto que se desea desarrollar. Éstos
consisten usualmente en los servicios que debe proveer, limitaciones y metas del
software. Una vez que se ha establecido esto, los requerimientos deben ser
definidos en una manera apropiada para ser útiles en la siguiente etapa. Esta
etapa incluye también un estudio de la factibilidad y viabilidad del proyecto
con el fin de determinar la conveniencia de la puesta en marcha del proceso de
desarrollo. Puede ser tomada como la concepción de un producto de software y
ser vista como el comienzo del ciclo de vida.
Diseño del sistema:
el diseño del software es un proceso multipaso que se centra en cuatro
atributos diferentes de los programas: estructura de datos, arquitectura del
software, detalle del proceso y caracterización de las interfases. El proceso de
diseño representa los requerimientos en una forma que permita la codificación
del producto (además de una evaluación de la calidad previa a la etapa de
codificación). Al igual que los requerimientos, el diseño es documentado y se
convierte en parte del producto de software.
Implementación:
esta es la etapa en la cual son creados los programas. Si el diseño posee un
nivel de detalle alto, la etapa de codificación puede implementarse mecánicamente.
A menudo suele incluirse un testeo unitario en esta etapa, es decir, las
unidades de código producidas son evaluadas individualmente antes de pasar a la
etapa de integración y testeo global.
Testeo del sistema:
una vez concluida la codificación, comienza el testeo del programa. El proceso
de testeo se centra en dos puntos principales: las lógicas internas del
software; y las funcionalidades externas, es decir, se solucionan errores de
“comportamiento” del software y se asegura que las entradas definidas
producen resultados reales que coinciden con los requerimientos especificados.
Mantenimiento:
esta etapa consiste en la corrección de errores que no fueron previamente
detectados, mejoras funcionales y de performance, y otros tipos de soporte. La
etapa de mantenimiento es parte del ciclo de vida del producto de software y no
pertenece estrictamente al desarrollo. Sin embargo, mejoras y correcciones
pueden ser consideradas como parte del desarrollo.
Estas
son las etapas principales. También existen sub-etapas, dentro de cada etapa,
pero éstas difieren mucho de un proyecto a otro. También es posible que
ciertos proyectos de software requieran la incorporación de una etapa extra o
la separación de una etapa en otras dos. Sin embargo, todas estas variaciones
al modelo cascada poseen el mismo concepto básico: la idea de que una etapa
provee salidas que serán usadas como las entradas de la siguiente etapa (un
flujo lineal entre las etapas). Por lo tanto, el progreso del proceso de
desarrollo de un producto de software, usando el modelo cascada, es simple de
conocer y controlar.
Problemas con el Modelo Cascada
El
ciclo de vida clásico es el paradigma más viejo y el más ampliamente usado en
la ingeniería del software. Sin embargo, su aplicabilidad en muchos campos ha
sido cuestionada. Entre los problemas que aparecen cuando se aplica el modelo
cascada están:
Los proyectos raramente siguen el
flujo secuencial que el modelo propone. La iteración siempre es necesaria y está
presente, creando problemas en la aplicación del modelo.
A menudo es difícil para el
cliente poder especificar todos los requerimientos explícitamente. El modelo de
vida del software clásico requiere esto y presenta problemas acomodando la
incertidumbre natural que existe al principio de cualquier proyecto.
El cliente debe ser paciente. Una
versión funcional del sistema no estará disponible hasta tarde en la duración
del desarrollo. Cualquier error o malentendido, si no es detectado hasta que el
programa funcionando es revisado, puede ser desastroso.
Cada
uno de estos problemas es real. Sin embargo, el modelo clásico del ciclo de
vida del software tiene un lugar bien definido e importante en los trabajos de
ingeniería del software. Provee un patrón dentro del cual encajan métodos
para el análisis, diseño, codificación y mantenimiento.
El
modelo cascada se aplica bien en situaciones en las que el software es simple y
en las que el dominio de requerimientos es bien conocido, la tecnología usada
en el desarrollo es accesible y los recursos están disponibles.
Dos
de las críticas que se hacían al modelo de ciclo de vida en cascada eran que
es difícil tener claros todos los requisitos del sistema al inicio del
proyecto, y que no se dispone de una versión operativa del programa hasta las
fases finales del desarrollo, lo que dificulta la detección de errores y deja
también para el final el descubrimiento de los requisitos inadvertidos en las
fases de análisis. Para paliar estas deficiencias se ha propuesto un modelo de
ciclo de vida basado en la construcción de prototipos.
En
primer lugar, hay que ver si el sistema que tenemos que desarrollar es un buen
candidato a utilizar el paradigma de ciclo de vida de construcción de
prototipos o al modelo en espiral. En general, cualquier aplicación que
presente mucha interacción con el usuario, o que necesite algoritmos que puedan
construirse de manera evolutiva, yendo de lo mas general a lo más específico
es una buena candidata. No obstante, hay que tener en cuenta la complejidad: si
la aplicación necesita que se desarrolle una gran cantidad de código para
poder tener un prototipo que enseñar al usuario, las ventajas de la construcción
de prototipos se verán superadas por el esfuerzo de desarrollar un prototipo
que al final habrá que desechar o modificar mucho. También hay que tener en
cuenta la disposición del cliente para probar un prototipo y sugerir
modificaciones de los requisitos. Puede ser que el cliente ‘no tenga tiempo
para andar jugando’ o ‘no vea las ventajas
de este método de desarrollo’.
También es conveniente construir prototipos para probar la eficiencia de los algoritmos que se van a implementar, o para comprobar el rendimiento de un determinado componente del sistema en condiciones similares a las que existirán durante la utilización del sistema. Es bastante frecuente que el producto de ingeniería desarrollado presente un buen rendimiento durante la fase de pruebas realizada por los ingenieros antes de entregarlo al cliente pero que sea muy ineficiente, o incluso inviable, a la hora de almacenar o procesar el volumen real de información que debe manejar el cliente. En estos casos, la construcción de un prototipo de parte del sistema y la realización de pruebas de rendimiento, sirven para decidir, antes de empezar la fase de diseño, cuál es el modelo más adecuado de entre la gama disponible para el soporte hardware o cómo deben hacerse los accesos para obtener buenas respuestas en tiempo cuando la aplicación esté ya en funcionamiento.
En
otros casos, el prototipo servirá para modelar y poder mostrar al cliente cómo
va a realizarse la E/S de datos en la aplicación, de forma que éste pueda
hacerse una idea de como va a ser el sistema final, pudiendo entonces detectar
deficiencias o errores en la especificación aunque el modelo no sea más que
una cáscara vacía.
Según
esto un prototipo puede tener alguna de las tres formas siguientes:
un prototipo, en papel o ejecutable en ordenador, que describa la
interacción hombre-máquina y los listados del sistema.
un prototipo que implemente algún(os) subconjunto(s) de la función
requerida, y que sirva para evaluar el rendimiento de un algoritmo o las
necesidades de capacidad de almacenamiento y velocidad de cálculo del
sistema final.
un programa que realice en todo o en parte la función deseada pero que tenga características (rendimiento, consideración de casos particulares, etc.) que deban ser mejoradas durante el desarrollo del proyecto.
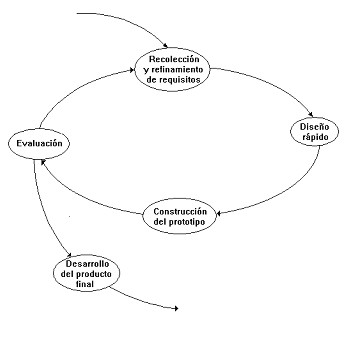
La
secuencia de tareas del paradigma de construcción de prototipos puede verse en
la siguiente figura.
|
|
Luego
se procede a diseñar el prototipo. Se tratará de un diseño rápido, centrado
sobre todo en la arquitectura del sistema y la definición de la estructura de
las interfaces más que en aspectos de procedimiento de los programas: nos
fijaremos más en la forma y en la apariencia que en el contenido.
A
partir del diseño construiremos el prototipo. Existen herramientas
especializadas en generar prototipos ejecutables a partir del diseño. Otra opción
sería utilizar técnicas de cuarta generación. La posibilidad más reciente
consiste en el uso de especificaciones formales, que faciliten el desarrollo
incremental de especificaciones y permitan la prueba de estas especificaciones.
En
cualquier caso, el objetivo es siempre que la codificación sea rápida, aunque
sea en detrimento de la calidad del software generado.
Una
vez listo el prototipo, hay que presentarlo al cliente para que lo pruebe y
sugiera modificaciones. En este punto el cliente puede ver una implementación
de los requisitos que ha definido inicialmente y sugerir las modificaciones
necesarias en las especificaciones para que satisfagan mejor sus necesidades.
A
partir de estos comentarios del cliente y los cambios que se muestren necesarios
en los requisitos, se procederá a construir un nuevo prototipo y así
sucesivamente hasta que los requisitos queden totalmente formalizados, y se
pueda entonces empezar con el desarrollo del producto final.
Por
tanto, el prototipado es una técnica que sirve fundamentalmente para la fase de
análisis de requisitos, pero lleva consigo la obtención de una serie de
subproductos que son útiles a lo largo del desarrollo del proyecto:
Gran parte del trabajo realizado durante la fase de diseño rápido
(especialmente la definición de pantallas e informes) puede ser utilizada
durante el diseño del producto final. Además, tras realizar varias vueltas
en el ciclo de construcción de prototipos, el diseño del mismo se parece
cada vez más al que tendrá el producto final.
Durante la fase de construcción de prototipos será necesario codificar algunos componentes del software que también podrán ser reutilizados en la codificación del producto final, aunque deban de ser optimizados en cuanto a corrección o velocidad de procesamiento.
No
obstante, hay que tener en cuenta que el prototipo no es el sistema final,
puesto que normalmente apenas es utilizable. Será demasiado lento, demasiado
grande, inadecuado para el volumen de datos necesario, contendrá errores
(debido al diseño rápido), será demasiado general (sin considerar casos
particulares, que debe tener en cuenta el sistema final) o estará codificado en
un lenguaje o para una máquina inadecuadas, o a partir de componentes software
previamente existentes. No hay que preocuparse de haber desperdiciado tiempo o
esfuerzos construyendo prototipos que luego habrán de ser desechados, si con
ello hemos conseguido tener más clara la especificación del proyecto, puesto
que el tiempo perdido lo ahorraremos en las fases siguientes, que podrán
realizarse con menos esfuerzo y en las que se cometerán menos errores que nos
obliguen a volver atrás en el ciclo de vida.
Hay
que tener en cuenta que un análisis de requisitos incorrecto o incompleto,
cuyos errores y deficiencias se detecten a la hora de las pruebas o tras
entregar el software al cliente, nos obligará a repetir de nuevo las fases de
análisis, diseño y codificación, que habíamos realizado cuidadosamente,
pensando que estábamos desarrollando el producto final. Al tener que repetir
estas fases, sí que estaremos desechando una gran cantidad de trabajo,
normalmente muy superior al esfuerzo de construir un prototipo basándose en un
diseño rápido, en la reutilización de trozos de software preexistentes y en
herramientas de generación de código para informes y manejo de ventanas.
Uno
de los problemas que suelen aparecer siguiendo el paradigma de construcción de
prototipos, es que con demasiada frecuencia el prototipo pasa a ser parte del
sistema final, bien sea por presiones del cliente, que quiere tener el sistema
funcionando lo antes posible o bien porque los técnicos se han acostumbrado a
la máquina, el sistema operativo o el lenguaje con el que se desarrolló el
prototipo. Se olvida aquí que el prototipo ha sido construido de forma
acelerada, sin tener en cuenta consideraciones de eficiencia, calidad del
software o facilidad de mantenimiento, o que las elecciones de lenguaje, sistema
operativo o máquina para desarrollarlo se han hecho basándose en criterios
como el mejor conocimiento de esas herramientas por parte los técnicos que en
que sean adecuadas para el producto final.
El utilizar el prototipo en el producto final conduce a que éste contenga numerosos errores latentes, sea ineficiente, poco fiable, incompleto o difícil de mantener. En definitiva a que tenga poca calidad, y eso es precisamente lo que se quiere evitar aplicando la ingeniería del software.
El
problema con los modelos de procesos de software es que no se enfrentan lo
suficiente con la incertidumbre inherente a los procesos de software.
Importantes proyectos de software fallaron porque los riegos del proyecto se
despreciaron y nadie se preparó para algún imprevisto. Boehm reconoció esto y
trató de incorporar el factor “riesgo del proyecto” al modelo de ciclo de
vida, agregándoselo a las mejores características de los modelos Cascada y
Prototipado. El resultado fue el Modelo Espiral. La dirección del nuevo modelo
fue incorporar los puntos fuertes y evitar las dificultades de otros modelos
desplazando el énfasis de administración hacia la evaluación y resolución
del riesgo. De esta manera se permite tanto a los desarrolladores como a los
clientes detener el proceso cuando se lo considere conveniente.
|
|
Descripción del modelo
Básicamente,
la idea es desarrollo incremental usando el modelo Cascada para cada paso,
ayudando a administrar los riesgos. No se define en detalle el sistema completo
al principio; los diseñadores deberían definir e implementar solamente los
rasgos de mayor prioridad. Con el conocimiento adquirido, podrían entonces
volver atrás y definir e implementar más características en trozos más pequeños.
El
modelo Espiral define cuatro actividades principales en su ciclo de vida:
Planeamiento: determinación de los
objetivos, alternativas y limitaciones del proyecto.
Análisis de riesgo: análisis de
alternativas e identificación y solución de riesgos.
Ingeniería: desarrollo y testeo
del producto.
Evaluación del cliente: tasación
de los resultados de la ingeniería.
El
modelo está representado por una espiral dividida en cuatro cuadrantes, cada
una de las cuales representa una de las actividades arriba mencionadas.
Puntos fuertes
Evita las dificultades de los
modelos existentes a través de un acercamiento conducido por el riesgo.
Intenta eliminar errores en las
fases tempranas.
Es el mismo modelo para el
desarrollo y el mantenimiento.
Provee mecanismos para la aseguración
de la calidad del software.
La reevaluación después de cada
fase permite cambios en las percepciones de los usuarios, avances tecnológicos
o perspectivas financieras.
La focalización en los objetivos y
limitaciones ayuda a asegurar la calidad.
Puntos débiles
Falta un proceso de guía explícito
para determinar objetivos, limitaciones y alternativas.
Provee más flexibilidad que la
conveniente para la mayoría de las aplicaciones.
La pericia de tasación del riesgo
no es una tarea fácil. El autor declara que es necesaria mucha experiencia en
proyectos de software para realizar esta tarea exitosamente.
Aplicación
Proyectos
complejos, dinámicos, innovadores, ambiciosos, llevados a cabo por equipos
internos (no necesariamente de software).
Cleanroom es un proceso de administración e ingeniería
para el desarrollo de software de alta calidad con fiabilidad certificada.
Focaliza la atención en la prevención en lugar de la corrección de errores, y
la certificación de la fiabilidad del software para el entorno de uso para cual
fue planeado. En lugar de realizar pruebas de unidades y módulos, se
especifican formalmente componentes de software los cuales son verificados matemáticamente
en cuanto son construidos.
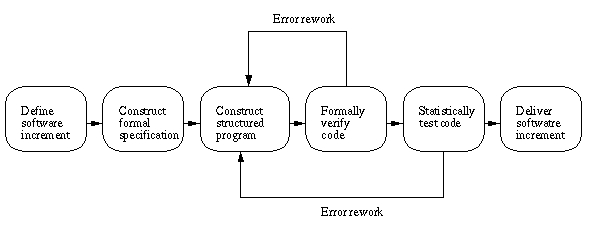
Descripción del modelo
|
|
El modelo tiene las siguientes características:
Desarrollo
incremental: el software
es particionado en incrementos los cuales se desarrollan utilizando el
proceso cleanroom.
Especificación formal: el software
a desarrollarse es formalmente especificado.
Verificación estática: el
software desarrollado es verificado matemáticamente (los desarrolladores no
pueden ejecutar el código) utilizando argumentos de correctitud basados en
matemáticas. No hay pruebas a nivel unidad o módulo.
Pruebas estadísticas: el
incremento de software integrado es examinado estadísticamente para determinar
su fiabilidad.
Hay tres equipos involucrados en el proceso de
cleanroom:
El equipo de especificación: este
equipo es responsable del desarrollo y mantenimiento de las especificaciones del
sistema. Ambas especificaciones, las orientadas al cliente.
El equipo de desarrollo: este
equipo tiene la responsabilidad de desarrollar y verificar el software.
El equipo de certificación: este
equipo es responsable del desarrollo de un conjunto de pruebas estadísticas
para ejercitar el software una vez que fue construido.
Cleanroom provee las prácticas de
administración e ingeniería que permiten a los equipos lograr cero fallos en
el campo de uso, cortos ciclos de desarrollo, y una larga vida del producto.
Reduce los fallos encontrados
durante el proceso de certificación a menos de cinco fallos por cada mil líneas
de código en la primera ejecución del código del primer proyecto.
Equipos nuevos deberían
experimentar un incremento del doble en la productividad con respecto a su
primer proyecto. La productividad seguirá incrementándose con la experiencia
adquirida.
Cleanroom lleva a una inversión en
bienes tales como especificaciones detalladas y modelos que ayudan a mantener un
producto viable durante una vida más larga.
Todos los beneficios técnicos se
trasladan en beneficios económicos significantes.
Aplicación
El
método cleanroom es mandatorio para cualquier sistema de software de misión crítica;
sin embargo es apto para cualquier proyecto de software, en especial si el
proyecto requiere detección de errores en fases tempranas.
5.1. Comparación entre los modelos.
La
siguiente tabla muestra una comparación entre los cuatro modelos más
utilizados:
|
Criterio |
Cascada |
Prototipado |
Cleanroom |
Espiral |
|
Disponibilidad
de recursos |
Todos |
Algunos |
Algunos |
Algunos |
|
Complejidad
del proyecto |
Baja |
Media |
Alta |
Alta |
|
Entendimiento
de los requerimientos |
Específico |
Vago |
Vago |
Vago |
|
Tecnología
del producto |
Vieja |
Nueva |
Nueva |
Nueva |
|
Volatilidad
de requerimientos |
No |
Si |
Si |
Si |
|
Manejo
de la perspectiva del riesgo |
No |
Si |
No |
Si |
|
Conocimiento
del dominio del problema |
Alto |
Regular |
Alto |
Pobre |
Los métodos presentados tienen un campo de aplicación bien definido;
sin embargo, los problemas reales con los que un equipo de desarrollo puede
enfrentarse no calzan de manera perfecta en los dominios para los cuales los métodos
fueron pensados. Es tarea de los ingenieros adaptar un método o componer uno
nuevo a partir de los métodos existentes para conseguir una solución que se
amolde al problema en particular que se está atacando. En definitiva, es el
problema el que propone la solución (o al menos el camino a la solución).
Conclusiones.
Independientemente
del paradigma que se utilice, del área de aplicación, y del tamaño y la
complejidad del proyecto, el proceso de desarrollo de software contiene siempre
una serie de fases genéricas, existentes en todos los paradigmas. Estas fases
son la definición, el desarrollo y el mantenimiento.
Definición.
La fase de definición se centra en el qué.
Durante esta fase, se intenta identificar:
qué información
es la que tiene que ser procesada.
qué función
y rendimiento son los que se esperan.
qué
restricciones de diseño existen.
qué
interfaces deben utilizarse.
qué lenguaje
de programación, sistema operativo y soporte hardware van a ser utilizados.
qué criterios
de validación se necesitan para conseguir que el sistema final sea correcto.
Aunque
los pasos concretos dependen del modelo de ciclo de vida utilizado, en general
se realizarán tres tareas específicas:
Análisis
del sistema.
El
análisis del sistema define el papel de cada elemento de un sistema informático,
estableciendo cuál es el papel del software dentro de ese sistema.
Análisis
de requisitos del software.
El
análisis del sistema proporciona el ámbito del software, su relación con el
resto de componentes del sistema, pero antes de empezar a desarrollar es
necesario hacer una definición más detallada de la función del software.
Planificación
del proyecto software.
Durante esta etapa se lleva a cabo el análisis de riesgos, se definen los recursos necesarios para desarrollar el software y se establecen las estimaciones de tiempo y costes. El propósito de esta etapa de planificación es proporcionar una indicación preliminar de la viabilidad del proyecto de acuerdo con el coste y con la agenda que se hayan establecido. Posteriormente, la gestión del proyecto durante el desarrollo del mismo realiza y revisa el plan de proyecto de software.
Desarrollo.
La fase de definición se centra en el cómo.
cómo ha de ser la arquitectura de la aplicación.
cómo han de ser las estructuras de datos.
cómo han de implementarse los detalles de procedimiento de los módulos.
cómo van a ser los interfaces.
cómo ha de traducirse el diseño a un lenguaje de programación.
cómo van a realizarse las pruebas.
Aunque, al igual que antes,
los pasos concretos dependen del modelo de ciclo de vida utilizado, en
general se realizarán cuatro tareas específicas:
Diseño.
El
diseño del software traduce los requisitos a un conjunto de representaciones
(gráficas, en forma de tabla o basadas en algún lenguaje apropiado) que
describen cómo van a estructurarse los datos, cuál va a ser la arquitectura de
la aplicación, cuál va a ser la estructura de cada programa y cómo van a ser
las interfaces. Es necesario seguir criterios de diseño que nos permitan
asegurar la calidad del producto.
Una
vez finalizado el diseño es necesario revisarlo para asegurar la completitud y
el cumplimiento de los requisitos del software.
Codificación.
En
esta fase, el diseño se traduce a un lenguaje de programación, dando como
resultado un programa ejecutable. La buena calidad de los programas
desarrollados depende en gran medida de la calidad del diseño.
Una
vez codificados los programas debe revisarse su estilo y claridad, y se
comprueba que haya una correspondencia con la estructura de los mismos definida
en la fase de diseño.
Pruebas.
Una
vez que tenemos implementado el software es preciso probarlo, para detectar
errores de codificación, de diseño o de especificación. Las pruebas son
necesarias para encontrar el mayor número posible de errores antes de entregar
el programa al cliente.
Es
necesario probar cada uno de los componentes por separado (cada uno de los módulos
o programas) para comprobar el rendimiento funcional de cada una de estas
unidades.
A
continuación se procede a integrar los componentes para probar toda la
arquitectura del software, y probar su funcionamiento y las interfaces. En este
punto hay que comprobar si se cumplen todos los requisitos de la especificación.
Se puede desarrollar un plan y procedimiento de pruebas y guardar información sobre los casos de pruebas y los resultados de las mismas.
Garantía
de calidad.
Una vez terminada la fase de pruebas, el software está
casi preparado para ser entregado al cliente.
Mantenimiento.
La
fase de mantenimiento se centra en los cambios que va a sufrir el software a lo
largo de su vida útil. Como ya hemos dicho, estos cambio pueden deberse a la
corrección de errores, a cambios en el entorno inmediato del software o a
cambios en los requisitos del cliente, dirigidos normalmente a ampliar el
sistema.
La
fase de mantenimiento vuelve a aplicar los pasos de las fases de definición y
de desarrollo, pero en el contexto de un software ya existente y en
funcionamiento.
http://243.sip.ucm.es/is/intro.html
http://www.centersoft.co.cu/Desasoft.htm
http://members.tripod.cl/RuthGarrido/ingsof/cap2-4.html
http://www.reduaeh.mx/presenta/univirtual/notas_2.htm