Esta sección tiene como objetivo presentar un estudio de los sistemas multiprocesadores desde el punto de vista del aumento de rendimiento (Speed-up) y del tiempo de ejecución segśn el nśmero de procesadores y el tamańo de la caché, propiedades que se consideran crķticas para hacer un sistema con una buena relación entre las prestaciones y el coste del mismo. Todo ello utilizando el simulador Limes con una serie de programas.
El anįlisis se centra en dos puntos muy importantes en los sistemas multiprocesador desde el punto de vista de la coherencia de los datos, el protocolo de caché y el método de sincronización. Con respecto al primero, los analizados se basan śnicamente en sondeo (Snoopy), con dos ejemplos de invalidación (MESI y Berkeley) y uno de actualización (Dragón), del segundo se tratan dos ejemplos de algoritmos basados en barrera (Sense-Reversing y Arbol). Se intenta pues, llegar a conclusiones sobre las prestaciones y tiempos de ejecución de las configuraciones explicįndolas coherentemente.
Ademįs de estos aspectos se dedica una parte de la sección a un problema realmente importante en los sistemas multiprocesador basados en bus, la falsa compartición, que puede disminuir notablemente el rendimiento del mismo si no se hace una buena elección del protocolo de caché para un tamańo de caché y nśmero determinado de procesadores.
Los apartados son:
- Estudio comparativo de protocolos de caché .
- Problema de la falsa compartición
- Acceso a variables compartidas, sincronización .
- Estudio comparativo de protocolos de caché. En esta sección se analizan los distintos protocolos de caché (MESI, Berkeley y Dragón) sobre variaciones de tamańo de caché y nśmero de procesadores, llegando a conclusiones de las ventajas e inconvenientes de cada uno en cada una de estas configuraciones. Ademįs, se obtienen resultados de las propiedades de aplicarlos sobre el sistema con inicialización y sin inicialización.
- Rendimiento segśn nśmero de procesadores y caché de 8KB.
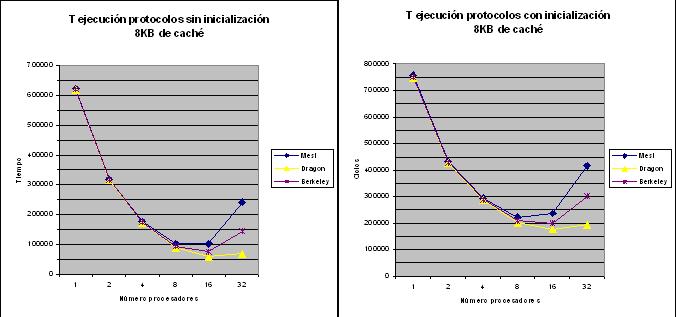
Analizando comparativamente ambas grįficas respecto a considerar la inicialización o no, en el segundo caso el sistema es mįs rįpido, hasta un 37%, esto es debido a que el periodo de inicialización significa un tiempo extra en el proceso de ejecución en el que se realizan tareas poco paralelizables como repartir a los procesadores sus procesos, en consecuencia los tres protocolos tienen casi el mismo comportamiento puesto que no pueden sacar jugo de sus propiedades pensadas para la ejecución concurrente, que es lo que se puede observar en la grįfica del rendimiento.
Con respecto al t.ejecución segśn el protocolo y el nśmero de procesadores, como se puede observar en ambas, hasta 8 procesadores se obtienen aproximadamente los mismos resultados, aproximadamente 100000 ciclos sin inicialización, pero en adelante el tiempo varķa segśn el protocolo, con un aumento notable para MESI (150%), y Berkeley(50%) asķ como una disminución mķnima para Dragón (40%).
Esto es debido a que los protocolos de invalidación cuando ocurre un fallo de escritura o de lectura tienen que invalidar todas las copias del resto de procesadores que la poseen, con lo cual estos en los siguientes ciclos tendrįn que acceder a memoria a por la nueva copia después de haber fallado al intentar leer, lo cual significara un incremento del trįfico en el bus y por tanto se requerirį mįs tiempo para efectuar todas estas lecturas a memoria principal y continuar con la ejecución. Para pocos procesadores este proceso casi no significa perdida de tiempo pero a medida que aumenta el nśmero puede ser importante y un problema.
En el caso del Berkeley la mejorķa con respecto al MESI es debida a que en lugar de acceder a memoria todos a por el bloque invalidado acceden al que tiene el correcto que ejerce de esta tarea con lo cual aunque este pierda prestaciones el sistema en general es mįs rįpido puesto que no todos acceden memoria a leer todas los bloques sino que todos hacen esta función con los bloques exclusivos.
Por el contrario, Dragón, al ser un protocolo de actualización cuando modifica su copia se modifica la del resto con lo cual cuando estos hagan lectura del bloque no fallaran y no harįn todos lectura a memoria, eliminando todo el tiempo de acceso de todos a hacer lecturas para obtener las copias validadas, por esta razón para un nśmero de procesadores alto no aumenta el tiempo de ejecución.
En las siguientes grįficas se puede observar los comentados en el aumento del rendimiento (Speed-up) y su comparación con el ideal.
El resultado directo de contabilizar la inicialización es la disminución del rendimiento, alejįndolo desde 4 procesadores de las posibilidades ideales, es decir con una escalabilidad hasta 2 procesadores. Por el contrario sin contabilizar la inicialización la escalabilidad aumenta hasta 8 procesadores puesto que hasta este valor el speed-up real se acerca al ideal.
Con respecto a los protocolos, el rendimiento de todos a partir de 16 procesadores disminuye aunque es mįs importante en el caso de los de invalidación como se ha comentado anteriormente. A partir de 16 procesadores se observa ademįs que se aleja de las posibilidades ideales con lo cual no seria recomendable para esta configuración no superar este nśmero y no obtener una mala relación coste-rendimiento.
- Rendimiento comparativo segśn nśmero procesadores en caché de 8KB y 256KB
En este apartado se intenta observar como influye el aumento del tamańo de la caché en el nśmero de procesadores y el protocolo utilizado. De manera comparativa se eligen dos tamańos 8 y 256 KB que difieren bastante y de esta forma observar como se comporta aumentando suficientemente el tamańo.
En primer lugar se muestran las grįficas del tiempo de ejecución sin tener en cuenta la inicialización, puesto que de ese aspecto ya se ha hablado antes:
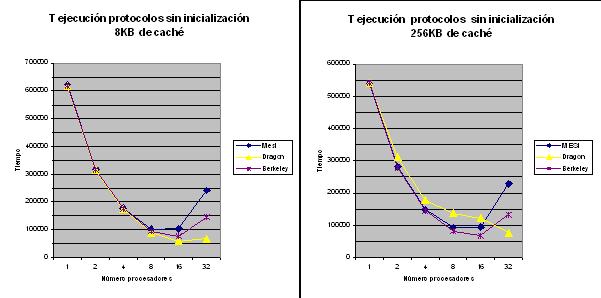
La principal diferencia entre ambas grįficas reside en el hecho de que el protocolo Dragon aumenta el tiempo de ejecución para 4, 8 y 16 procesadores hasta aproximadamente un 60% en 16 procesadores.
Ademįs, en general, se observa una disminución del tiempo del tiempo de ejecución hasta 4 procesadores y un aumento en adelante.
El tamańo de caché esta directamente relacionado con el nśmero de bloques que puede albergar, de forma que dado un tamańo fijo de bloque, albergara un mayor nśmero cuanto mayor sea esta, con lo cual habrį mįs probabilidad que una caché lo contenga y que este mįs tiempo sin desalojar por haber mįs espacio, y por el contrario menos de que se produzca fallo por no encontrarse en caché, en consecuencia disminuye el nśmero de accesos a memoria y las transacciones de bus, por eso en general se observa una disminución del tiempo de ejecución.
Al aumentar la probabilidad de que un procesador contenga un bloque determinado en su caché y que este mįs tiempo sin ser desalojado, si se trata de un protocolo de invalidación cuando un procesador realice una escritura de un dato, posiblemente tendrį que invalidar mįs copias, que no serį significativo, pero que ademįs si no se vuelven a utilizar probablemente sean desalojadas antes de producir un fallo por realizar una nueva lectura/escritura, es eso por lo que el comportamiento no varia entre tamańos de caché.
Para el protocolo Dragon, actualización, al haber mįs copias en mįs procesadores tiene que actualizarlas todas aunque estas no se utilicen, puesto que quizįs fueron leķdas en un cierto momento para una operación śnicamente pero al haber mįs memoria aun no han sido desalojadas, con lo cual hace actualizaciones innecesarias de copias q no se utilizan que genera trįfico innecesario, mayor tiempo de ejecución y disminución del rendimiento.
Muy importante es ademįs el hecho de que los desalojos de la caché y en consecuencia los resultados obtenidos también dependen de la utilización de las variables en el programa que es consecuencia de la implementación del mismo.
En los grįficos siguientes se observa los efectos de lo explicado sobre el Speed-up:
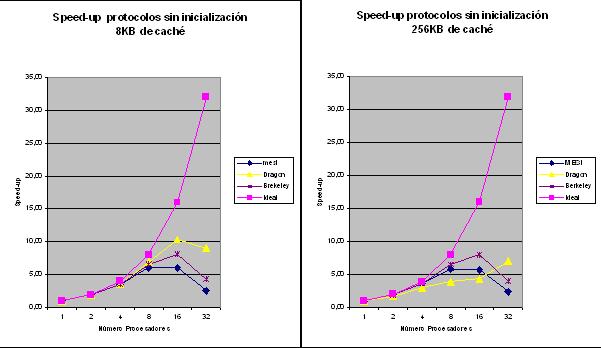
Se observa que la escalabilidad del sistema bajo el protocolo dragón disminuye de 8 a 4 como consecuencia de los efectos del aumento del tamańo de caché. Del MESI y Berkeley se mantienen en el mismo valor
- Rendimiento segśn tamańo de caché con 4 procesadores.
Este śltimo śltimo apartado trata de analizar como se comporta un sistema segśn el protocolo utilizado modificando el tamańo de caché utilizado bajo un nśmero de procesadores fijo.
En primer lugar se muestran los resultados de los tiempos de ejecución obtenidos tanto sin considerar como considerando la inicialización:
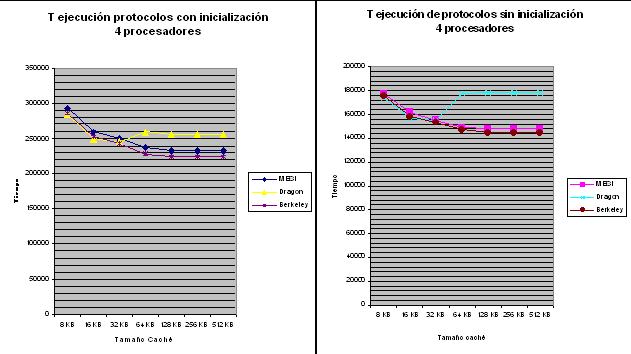
Con respecto a la inicialización como se puede ver se producen dos resultados, en primer lugar que disminuye el tiempo de ejecución si no se considera y en segundo lugar que también disminuye la diferencia del protocolo dragon con el resto.
Entre ambas, la caracterķstica mįs importante es el aumento del tiempo de ejecución del protocolo dragon con respecto del resto a partir de un tamańo determinado, manteniéndose constante. Desde 156.000 ciclos en 32KB, aumenta un 12% y se mantienen hasta 512KB, el resto disminuyen hasta 6%. En consecuencia hasta 32KB no serį muy importante el tipo de protocolo que se utilice puesto que tardaran aproximadamente lo mismo pero desde ese punto en adelante interesa uno de invalidación, aunque mejor el Berkeley por lo ya comentado en el punto anterior.
A medida que aumenta el tamańo, los protocolos de actualización necesitan actualizar mayor nśmero de copias en mas procesadores innecesariamente con lo cual disminuye el tiempo de ejecución.
La disminución en el tiempo de ejecución de los protocolos de invalidación hasta 64KB es debida a que hasta este valor no hay demasiados bloques en el procesador por lo que aunque se invalidan y se pierde tiempo accediendo a obtenerlo de nuevo por el resto después del fallo este tiempo es menor que el tiempo ganado por la tasa aciertos de escritura/lectura que se obtiene de mayor memoria.
A partir de 64KB las tasas de aciertos por mayor memoria y de fallos por invalidación se equilibran con lo cual por mucho que se aumente la memoria no se obtiene beneficio.
- Problema de la falsa compartición En una caché, sea cual sea el tipo, los datos son almacenados en lķneas de un tamańo determinado, de forma que cuando el procesador hace una lectura no lee un śnico dato sino que capta toda la lķnea para almacenarla en un buffer interno y trabajar con ella. Por otro lado, cuando se comparte una variable entre procesadores en un sistema como el que estamos tratando, segśn los protocolos de caché, cuando uno realiza una modificación en este dato tiene la obligación de invalidar o actualizar el resto de copias en los otros procesadores que la posean, aunque realmente el principal problema se produce, como ya se ha visto, cuando se invalidan muchas copias cuando hay bastantes procesadores. Puesto que como se ha comentado no se comparten realmente datos sino lķneas formadas de varios datos, cuando se invalida una variable por haber modificado su contenido, lo que realmente se hace es invalidar la lķnea. Aunque un procesador A trabaje con variable distinta a otra que posea otro procesador B, si estas se encuentran en la misma lķnea de caché, cuando A realice una escritura se invalidarį la lķnea y en consecuencia la del procesador B aunque sean diferentes variables. La consecuencia directa de este problema se encuentra en procesos que trabajan con datos continuos en memoria, por ejemplo vectores, lo que se observa que disminuyen mucho las prestaciones aunque cada procesador realice las operaciones sobre su propio subvector no compartido. En los próximos dos apartados se observa las consecuencias de este problema realizando dos tipos de reparto de datos de las lķneas de caché a los procesadores.
- Reparto consecutivo.
Trabajando con vectores de n elementos (en este caso 10000) y con m procesadores, en potencias de 2 hasta 64, se subdivide el vector en n/m trozos, dįndole a cada procesador cada uno. A partir de lo visto, se espera que cuando dos procesadores se encuentren en extremos contiguos parte de los datos estarįn localizados dentro de una misma lķnea de caché con lo cual se producirįn invalidaciones. Cuanto mayor sea el tamańo de la lķnea mįs elementos cabrįn y en consecuencia mįs invalidaciones se producirįn. Se ejecuta un proceso que realiza operaciones sobre un vector de n elementos repartiéndolo entre los procesadores existentes para que se hagan las operaciones concurrentemente en la medida de lo posible. Las siguientes grįficas muestran el T. ejecución y el aumento de rendimiento del mismo:
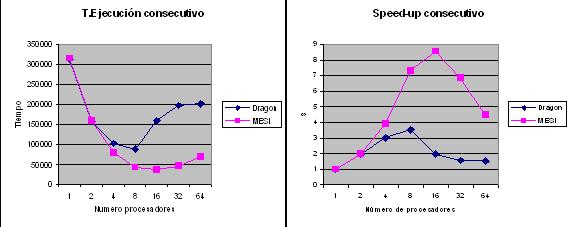
Con respecto al T. ejecución, manteniendo ambos parecidos tiempos hasta 4 procesadores, con los siguientes Dragon sufre una relentización importante, con casi un aumento del 100% y MESI mantiene tiempos bajos aumentando a partir de 16 hasta 64 un 75% aproximadamente.
Este incremento se produce por el hecho de haber mįs trozos y por tanto mįs lķneas compartidas. Los efectos se observan en el aumento del rendimientos, con una escalabilidad muy baja de solo 8 en MESI y 4 en Dragon, aunque a partir de 16 es mįs importante la caķda de rendimiento en MESI, de 8’5 a 4`5. Para este tipo de reparto se hace mįs eficiente MESI que dragon.
- Reparto entrelazado.
Con vectores de n elementos y m procesadores, ahora cada elemento es asignado a un procesador en función del ķndice, de forma que para i desde 0 a n-1 se asignarį al procesador [i mod m]+1. Con este reparto habrįn con mayor probabilidad mįs procesadores que compartan lķneas por tener datos contiguos, con lo cual los efectos deberķan ser mayores que con reparto anterior. Se realiza una ejecución sobre 10000 datos y n procesadores desde 2 a 64 en potencias de 2 y se obtienen los siguientes resultados de tiempo y rendimiento:
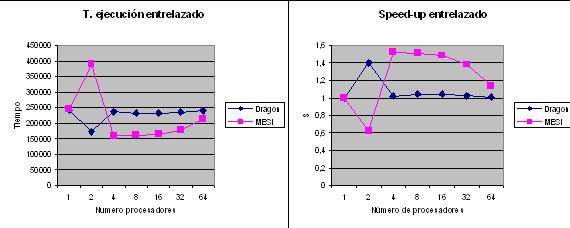
Analizando los tiempos de ejecución se argumenta los posibles efectos comentados, tanto MESI como Dragon tienen realizan una ejecución mįs lenta para todos los procesadores que en consecutivo. Con respecto a lo mįs importante destacar que se mantienen en unos tiempos casi constantes con MESI teniendo una ejecución mįs lenta a excepción con 2 procesadores que es este el q sufre un pico con un aumento significativo del tiempo y Dragon una disminución. Para este nśmero de procesadores las invalidaciones retrasan el sistema en gran medida. En la variación de rendimiento es donde se verifica que este método es mucho peor que el anterior llegando a unas prestaciones muy pobres que se alejan de las ideales en ambos protocolos con una escalabilidad de 1.
- Acceso a variables compartidas, sincronización.
- Barrera Sense-Reversing.
Consisten en sincronizar todos los elementos antes de una tarea, haciendo que hasta que todos no alcancen la misma no se continśe. Esta variación de barrera evita el problema de un bloqueo total producido en el caso de que uno se quedase colgado, para ello la variable que se utiliza para salir de la barrera se cambia asķ no hay posibilidad que se produzca lo anterior.
Cada procesador ejecuta el siguiente proceso:
void Proceso(void) { int i,pr,local_sense=1; LOCK(PrIdLock); pr=PrId; /* Cada identificador de proceso debe ser unico */ PrId++; /* por eso se protege con un cerrojo */ UNLOCK(PrIdLock); for (i=0; i <4; i++ ) { if (i==0) matriz[0][pr-1] = pr; else{ local_sense = !local_sense; // Evita bloqueo global LOCK(counterlock); // Primero que llega la cierra counter++; UNLOCK(counterlock); if(counter == n_pro) { // Han llegado todos a la barrera counter = 0; release = local_sense; }else // No estan todos -> while(release != local_sense); matriz[i][pr-1] = matriz[i-1][(pr-2+n_pro)%n_pro]; } } } donde las variables globales son: int matriz[4][PROC_MAX]; int PrId; /* Identificador de proceso */ int n_pro; /* Numero de procesadores totales */ int release = 1; int counter; /* Numero de procesadores en la barrera */ LOCKDEC(PrIdLock); /* Cerrojo usado para la variable anterior */ LOCKDEC(counterlock);Ejecutando el programa se obtienen los siguientes tiempos:
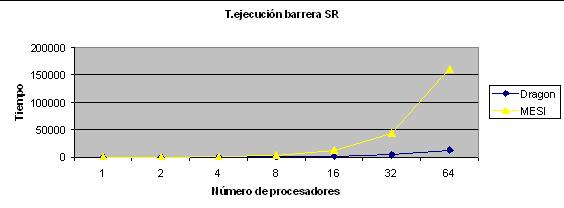
Que demuestran lo esperado, en primer lugar que los protocolos de actualización (dragon) ofrecen mejores tiempos que los de invalidación (MESI) para el caso de variables de sincronización y segundo que a partir de 16 procesadores no ofrece buenos resultados.
- Barrera en įrbol
A medida que aumentan el nśmero de procesadores las prestaciones de la Barrera SR disminuyen puesto que todos quieren acceder a count que es compatida y aumenta el trįfico del bus haciendo muchas lecturas continuadas a memoria. Con el fin de resolver este problema y eliminar el acceso de todos los procesadores a una variable compartida al mismo tiempo aparecen las barreras distribuidas (en įrbol), donde a modo de įrbol binario se hace una liberación jerarquizada.
El įrbol esta formado por nodos hoja que son los procesadores y nodos intermedios que son contadores, cuando llega un proceso a la barrera este sabe que nodo le toca por lo tanto incrementa su nodo padre, que si comprueba que han llegado todos los hijos hace release del padre y este sigue el mismo procedimiento incrementando su contador y comprobando. Cuando el nodo raķz comprueba que todos los hijos han llegado hace release global para reiniciar el proceso.
El programa que se utiliza es el siguiente:
void Proceso(void) { int i,pr; int num_hijos=0; LOCK(PrIdLock); pr=PrId; PrId++; UNLOCK(PrIdLock); matriz[0][pr-1]=pr; for(i=1;i<4;i++){ if((pr*2>PROC_MAX)&&(pr!=1)){ ALOCK(contalock,pr-1); contadores[pr/2 -1]++; AULOCK(contalock,pr-1); num_hijos=0; } if(pr*2<=PROC_MAX){ if(pr*2+1>PROC_MAX) num_hijos=1; else num_hijos=2; } while(num_hijos!=contadores[pr-1]); if ((pr!=1)&&(pr*2<=PROC_MAX)){ ALOCK(contalock,pr/2-1); contadores[pr/2-1]++; AULOCK(contalock,pr/2-1); } contadores[pr-1]=0; if (pr!=1) while(liberacion[pr-1]!=1); liberacion[pr-1]=0; if (pr*2+1<=PROC_MAX) liberacion[pr*2+1-1]=1; if (pr*2 <=PROC_MAX)liberacion[pr*2-1]=1; matriz[i][pr-1]=matriz[i-1][(pr-2+PROC_MAX)%PROC_MAX]; } } Las variables globales son: int PROC_MAX=1; int matriz[4][64]; #define LONGIT 10000 ALOCKDEC(contalock,64); LOCKDEC(PrIdLock); int liberacion[64]; int count=0, release=1; int PrId; int contadores[64]; unsigned int final,inicio;Cuyos resultados son:
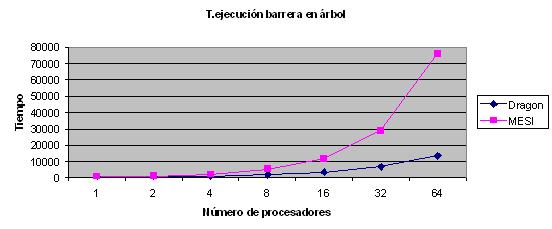
Sobre las conclusiones, se sigue corroborando que el protocolo Dragon es mįs eficiente pero lo mįs importante es observar que a partir de 32 procesadores se disminuye el tiempo de ejecución que es lo que se deseaba, pasando de alrededor de casi 50.000 ciclos para la barrera S-R a 30.000 en 32 procesadores y de 150.000 a 8.000 en 64.
El apartado se divide en 3 fases, dos de las cuales donde el objetivo principal es ver como afecta el nśmero de procesadores sobre un tamańo de caché fijo (8Kb y 256Kb) y un tercero cuyo fin es observar como se comporta sobre un nśmero de procesadores fijo (4) la variación del tamańo de caché. De las caracterķsticas, solo nos centraremos en el aumento de rendimiento (Speed-up) y el tiempo de ejecución, siendo las mįs importantes.
Del Speed-up, se incluye en las grįficas el ideal, para poder comparar con los obtenidos en las ejecuciones.
Generalmente cuando se crean programas de procesamiento de datos para multiprocesadores con el fin de aprovechar su potencia de cįlculo es necesaria cierta sincronización ya sea para compartir variables entre los procesadores o para controlar su ejecución sin que unos se adelanten a otros. Si estos mecanismos no se utilizaran la ejecución producirķa datos incorrectos.
Los algoritmos que se utilizan estįn basados en cerrojos que bloquean a los procesos a la espera de cierto evento ya sea la llegada del resto o que la sección crķtica sea abierta para trabajar con un dato determinado. Entre algunos de estos se encuentran los basados en barreras que son los que se plantean para analizar, aunque existen otros también importantes.
Las pruebas se realizan sobre una matriz de 4 x n, donde n es el nśmero de procesadores, el objetivo es que en 4 iteraciones se modifiquen los valores de cada fila desplazįndolos a la derecha, con lo cual cada procesador debe mover el dato en su fila a la siguiente y si esta al final pasarlo al principio. Esto hace necesario que el procesador i en la iteración m se tenga que esperar para copiar su dato al procesador i+1 mod n al procesador i-1 mod n que acabe de la iteración m-1.
Sin sincronización, los resultados son inconsistentes escribiendo 0 en las primeras posiciones por no disponer del dato correcto, por ello se hace necesario implementar algśn tipo de sincronización haciendo que el acceso a los datos sea una sección crķtica.